Recommended Blogs

Blog
Cloud Optimization for AI: How Enterprises Can Scale Intelligence Without Losing Cost Control

Table of Content
- Why AI Cloud Costs are Rising Faster Than Leaders Expected
- What Makes AI Cloud Spend Difficult to Control
- Cloud Optimization for AI Requires a Different Operating Model
- How Enterprises Can Reduce Cloud AI Costs Without Slowing Innovation
- How TxMinds Helps Enterprises Build Cost-Controlled AI at Scale
Share On



AI cloud spending usually starts with confidence. A team proves a model, launches a pilot, and shows early value. Then adoption grows. More users enter the workflow, more data moves through pipelines, and more model calls happen in the background. What once looked like a controlled innovation investment begins to behave like an unpredictable operating cost.
That is why cloud optimization for AI has become a leadership issue, not only a technical concern. The challenge is not to slow AI adoption. The challenge is to scale intelligence with enough visibility, architecture discipline, and cloud operations services maturity to protect cost control.
For C-level technology leaders, the real question is sharper now. Can the enterprise expand AI across products, operations, and decision workflows without creating a cloud cost model the business cannot explain?
This blog explores why AI cloud costs are rising, what makes them difficult to control, and how enterprises can use cloud optimization for AI to scale intelligence without losing cost discipline.
Key Takeaways
- AI cloud costs rise fast when pilots move into production across tokens, GPUs, data pipelines, retrieval, and inference.
- Gartner forecasts global IT spending to reach $6.15 trillion in 2026, with data center systems growing 31.7%.
- Flexera’s 2026 analysis found wasted IaaS and PaaS spend increased to 29%.
- FinOps Foundation says 98% of organizations now manage AI spend, up from 31% two years ago.
Why AI Cloud Costs are Rising Faster Than Leaders Expected
AI spend is rising because enterprise AI has moved from experiments into daily workflows. The cost profile changes once copilots, agents, and AI-enabled applications serve real users.
Gartner forecasts worldwide IT spending to reach $6.15 trillion in 2026, up 10.8% from 2025. It also projects data center systems spending to grow 31.7%, surpassing $650 billion in 2026, according to Gartner’s 2026 IT spending forecast.
The Pilot Cost Was Never the Full Cost
Early AI pilots often hide the real economics. Teams may test one model, one workflow, and one user group. Production behaves differently. More users, more prompts, more data, and more integrations quickly change the cost curve.
At scale, AI cloud cost expands across several layers:
- Model training and fine-tuning
- Inference calls and token usage
- GPU and accelerator capacity
- Vector databases and retrieval layers
- Data pipelines, storage, and movement
- Monitoring, security, and audit logging
- API calls across internal and external systems
The important shift is from occasional compute to persistent consumption. Every prompt, retrieval step, agent action, and model call carries cost.
Inference Is Becoming the Recurring Cost Center
Training gets attention because it looks expensive upfront. Inference often becomes more material because it happens continuously. Deloitte’s 2026 Tech Trends analysis says AI inference is forcing enterprises to rethink compute strategies. It highlights cost, scalability, and latency as key pressures in AI infrastructure planning.
This is where leaders need a sharper lens. The question is not whether AI works in the cloud. The better question is which AI workloads deserve which cloud architecture. That answer affects cost, resilience, compliance, and speed.
What Makes AI Cloud Spend Difficult to Control
AI cloud spend is hard to manage because it doesn’t behave like traditional cloud consumption. Traditional cloud costs usually map to servers, storage, bandwidth, or software seats. AI workloads add another layer of variability because usage depends on models, tokens, GPUs, data pipelines, and user behavior.
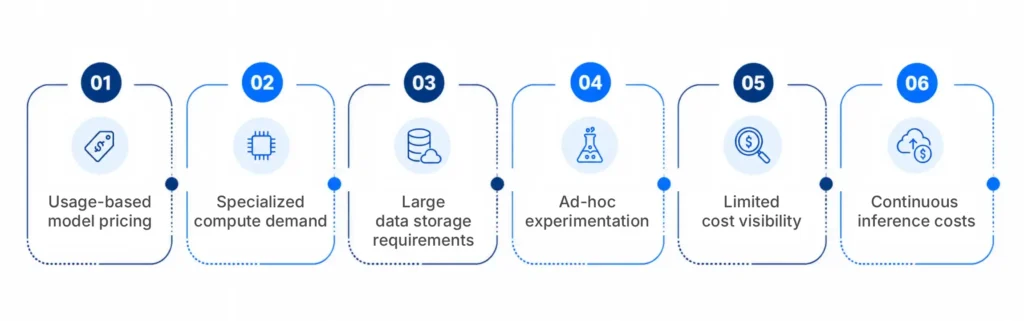
The Core Drivers of Unpredictable AI Spend
- Usage-based model pricing Many AI services charge based on tokens, API calls, or compute consumed during each request. A simple prompt, automated workflow, or sudden user surge can create higher costs than expected.
- Specialized compute demand Machine learning and generative AI workloads often depend on GPUs or accelerators. These resources are powerful, but they become costly when they are oversized, underused, or left running without clear controls.
- Large data storage requirements AI systems depend on high-volume data repositories, embeddings, model artifacts, logs, and training datasets. As teams create more AI workflows, storage and indexing costs can quietly expand.
- Ad-hoc experimentation Developers and data teams often test models, pipelines, and training jobs quickly. That speed supports innovation, but unmanaged experiments can consume compute before finance or platform teams see the cost impact.
- Limited cost visibility Standard cloud dashboards may not clearly separate AI expenses from broader application or infrastructure spend. Leaders can see total cost rising, but not always which model, workflow, or team caused it.
- Continuous inference costs Training may create a large upfront cost, but inference creates ongoing consumption. Once an AI tool becomes part of daily operations, every query, recommendation, summary, or agent action adds recurring spend.
For C-level leaders, the issue is not only that AI is expensive. The deeper concern is that AI cost can grow before ownership, governance, and business value are fully understood.
Cloud Optimization for AI Requires a Different Operating Model
Cloud optimization for AI needs more than traditional rightsizing or reserved instance planning. Those practices still help, but AI workloads also depend on model usage, token behavior, data movement, inference patterns, and governance discipline. The shift is already visible. The FinOps Foundation’s 2026 report says 98% of organizations now manage AI spend, up from 31% two years ago.
Business leaders need to move from cloud bills to AI unit economics. Instead of asking only what the platform costs, they should ask what each outcome costs. That may mean cost per customer interaction, generated report, claims summary, engineering workflow, or agentic task completion. This gives executives a clearer view of whether AI adoption is scaling with healthy economics.
Cost control should also be designed into architecture before production. Teams need clear standards for model selection, workload classification, tagging, token usage, observability, and approval paths for high-cost services. The tradeoff is real. Too much control slows experimentation, while too little control creates cost drift.
How Enterprises Can Reduce Cloud AI Costs Without Slowing Innovation
Enterprises can reduce cloud AI costs without slowing innovation when optimization becomes part of how AI is designed, deployed, and operated. The goal is not to restrict experimentation. The goal is to prevent avoidable waste while keeping high-value AI workloads moving.
-
Optimize Model Architecture and Workflows
Not every AI task needs the largest or most expensive model. Many enterprise use cases can run effectively on smaller models, open-weight models, or task-specific models. Leaders should focus on:
- Model-task fit: Use lighter models for extraction, classification, routing, and summarization.
- Prompt efficiency: Keep prompts focused, reusable, and free from unnecessary context.
- Retrieval control: Cache repeat queries and limit retrieval to relevant business data.
- Workflow simplification: Remove repeated model calls inside the same process.
-
Use AI-Led FinOps Practices
AI cost management should be continuous, not a monthly budget review. Teams need automated visibility into where spend is created and why it changes. Strong AI cloud cost management practices include:
- Predictive scaling: Provision compute only when workloads need it.
- Anomaly detection: Flag unusual spikes in model, token, or GPU usage early.
- Cost ownership: Assign spend to products, teams, workflows, and business units.
- Showback reporting: Help leaders connect AI usage with business outcomes.
-
Make Smarter Infrastructure Choices
The right infrastructure choice depends on workload behavior. Some AI workloads need high-performance GPUs, while others can run on lower-cost compute or specialized inference environments. Enterprises should evaluate:
- Specialized hardware: Use cost-efficient inference resources for predictable workloads.
- Spot or preemptible capacity: Run non-critical training or testing jobs at lower cost.
- Serverless patterns: Support variable workloads without paying for idle capacity.
- Hybrid placement: Run sensitive or predictable workloads outside public cloud when appropriate.
-
Strengthen Continuous Model Lifecycle Management
AI costs often rise when models, datasets, and pipelines are not reviewed after launch. Continuous lifecycle management keeps performance and cost aligned. Leaders should encourage:
- Automated retraining schedules: Avoid unnecessary retraining while maintaining model quality.
- Dataset governance: Reuse trusted datasets instead of rebuilding pipelines for every project.
- Model retirement: Remove unused models, endpoints, and experiments from active environments.
- Performance monitoring: Track accuracy, latency, cost, and user adoption together.
How TxMinds Helps Enterprises Build Cost-Controlled AI at Scale
At TxMinds, we help enterprises approach AI cost as an architecture and engineering control problem. We do not treat it as a billing cleanup exercise. We work with leaders to design AI-ready cloud foundations that support scale, governance, and measurable value. Our work connects AI-native engineering, data engineering, cloud architecture, platform scalability, and operational reliability.
We help teams build clearer AI cloud cost management practices across models, data pipelines, infrastructure, and production workflows. We also support workload assessment, architecture modernization, observability design, and governance models that make AI spend easier to forecast.
Our approach helps enterprises reduce cloud AI costs without weakening innovation. We build for disciplined scale, where AI adoption grows with cost visibility, trusted data, and engineering control.
VP, Delivery, Digital Engineering
Vivek Gupta is the Vice President of Delivery at Tx with over 25 years of experience driving digital transformation. At Tx, he has built the foundation for DevOps, Digital, and Cloud practices, shaping strategies that empower businesses. Before joining Tx, Vivek held leadership roles at Infosys and Tech Mahindra. His leadership fuels innovation, strengthens delivery excellence, and enhances Tx's global impact. Vivek's commitment to driving change ensures our clients stay ahead in an evolving digital landscape.
FAQs
What is cloud optimization for AI?
Cloud optimization for AI is the practice of designing AI workloads to run efficiently across compute, storage, data, inference, and model usage. It helps enterprises control cost while keeping AI systems scalable, reliable, and business-ready.
Why is AI cloud cost management harder than traditional cloud cost management?
AI cloud cost management is harder because AI spend depends on tokens, GPUs, model calls, data movement, retrieval layers, and continuous inference. A single AI workflow can trigger several cloud services before producing one business result.
How can enterprises reduce cloud AI costs without slowing innovation?
Enterprises can reduce cloud AI costs by using the right model for each task, optimizing prompts, improving retrieval design, right-sizing compute, and monitoring cost per workflow. The goal is better cost discipline, not less innovation.
What should leaders track when managing AI cloud costs?
Leaders should track cost per query, cost per workflow, token usage, GPU utilization, inference volume, data movement, and model performance. These metrics connect AI spending to business value more clearly.
Discover more