Recommended Blogs

Blog
Bad Data is Breaking AI: What Leaders Must Fix Before Scaling

Table of Content
- Data Quality for AI is Now a Business Performance Issue
- The Data Gaps That Break AI Before Production
- AI-Ready Data Means Trusted, Governed, and Usable Data
- A Leadership Playbook for Strengthening Data Quality for AI
- TxMinds’ Role in Building Data Foundations AI Can Trust
Share On



Most AI projects do not break because the model lacks sophistication. They break because the data feeding it cannot be trusted in real business conditions.
For C-level technology leaders, that shifts the conversation from model selection to data discipline. If the data is incomplete, duplicated, outdated, or fragmented across systems, AI only scales the weakness faster.
That is why data quality for AI must be addressed before pilots move into production workflows. Better data quality improves trust, reduces rework, strengthens governance, and helps AI initiatives create measurable enterprise value.
This blog explains where bad data breaks AI programs, what AI-ready data should look like, and how leaders can fix the foundation before AI scales.
Key Takeaways
- Stanford’s 2026 AI Index reports 88% organizational AI adoption, showing that AI is already moving into mainstream enterprise operations.
- Bad data makes AI outputs look confident but unreliable. The real risk is not only poor accuracy, but poor decisions at scale.
- AI-ready data is not a general enterprise label. It must fit the specific use case, workflow, business context, and risk level.
- Data quality for AI depends on practical disciplines such as observability, governance, feedback loops, and shared business ownership.
- AI becomes easier to govern and scale when data is trusted, traceable, monitored, and fit for the decisions it supports.
Data Quality for AI is Now a Business Performance Issue
Enterprise AI has moved beyond small experiments. The Stanford 2026 AI Index reports that organizational AI adoption reached 88%, showing how quickly AI has entered mainstream business operations.
That adoption creates a new leadership challenge. The question is no longer whether teams can access AI tools. The question is whether AI can act on data the enterprise trusts. AI does not fail in isolation. It fails inside business processes, customer journeys, risk decisions, and operational workflows. A poor recommendation in a dashboard may create confusion. A poor recommendation inside an AI-enabled workflow can trigger repeated errors at scale.
Bad data turns AI confidence into business risk
AI outputs often appear polished and decisive. That makes bad data more dangerous, not less. A customer service AI may recommend the wrong next action because account records are outdated. A claims triage model may misclassify urgency because documents are incomplete. A finance forecasting system may produce unreliable projections because regional definitions are inconsistent.
Poor data quality creates costs that leaders often underestimate. These costs spread across teams, budgets, governance, and adoption.
Common signs include:
- Business users manually checking AI outputs
- Data teams rebuilding pipelines under delivery pressure
- Governance teams adding late-stage reviews
- Product teams delaying AI releases
- Executives losing confidence after early failures
This is why data quality is no longer only a data team concern. It directly affects AI return, operating discipline, and enterprise decision confidence.
The Data Gaps That Break AI Before Production
AI teams often find the data problem after the business has already backed the use case. The model is ready, but the data cannot support the decision, workflow, or risk level expected from it.
That is the real answer behind why AI projects fail data quality checks late in delivery. The breakdown usually starts earlier, across source systems, definitions, ownership, and context.
| Data gap | What it does to AI |
|---|---|
| Fragmented systems | Creates conflicting views of customers, products, policies, finance, and operations. |
| Missing context | Leaves teams guessing about source quality, business meaning, ownership, and usage rights. |
| Duplicate records | Distorts patterns and makes some events appear more significant than they are. |
| Stale data | Trains or informs AI with business conditions that no longer apply. |
| Weak lineage | Makes it difficult to explain where an output came from or why it changed. |
At first, these gaps look manageable. Teams add manual checks, fix records case by case, and keep the project moving. That approach does not scale. Once AI enters production, weak data becomes a reliability problem for decisions, automation, and governance.
AI-Ready Data Means Trusted, Governed, and Usable Data
AI-ready data is not just cleaner data. Clean records can still lack ownership, lineage, access control, or business context. The supporting keyword AI readiness data should be understood through the use case. A fraud model, service chatbot, and pricing engine each need different evidence, controls, and freshness standards.
Leaders should avoid broad claims that enterprise data is ready for AI. A better test is whether the data is accurate, complete, consistent, secure, traceable, current, and monitored for the workflow it will support. This keeps governance practical. It gives teams enough control to manage risk without slowing AI delivery into another approval cycle.
A Leadership Playbook for Strengthening Data Quality for AI
Strong data quality for AI is not only a data team responsibility. It needs a leadership playbook that improves observability, governance, context, and feedback across the AI lifecycle.
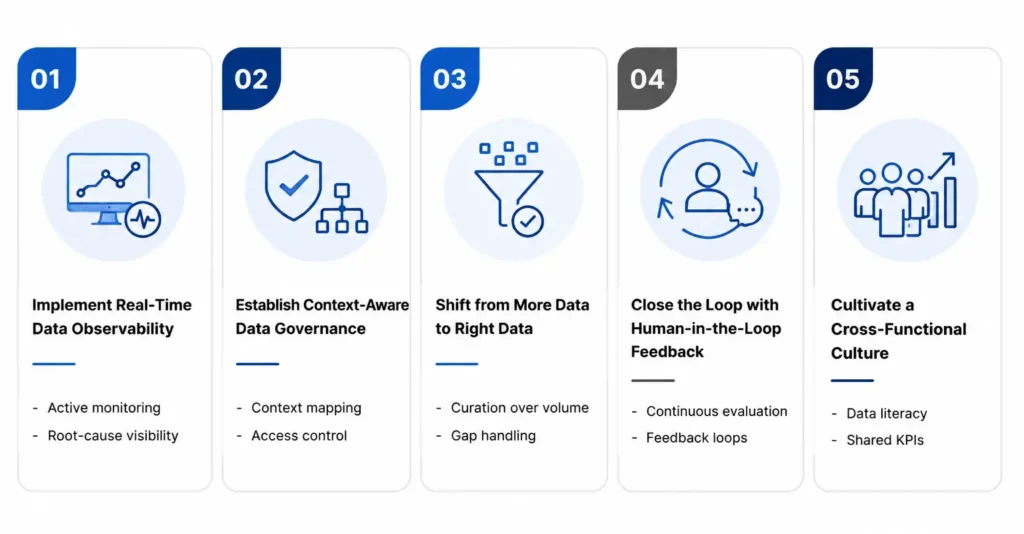
- Implement Real-Time Data Observability Traditional data quality checks are too slow for dynamic AI environments.
- Active monitoring: Track freshness, schema changes, missing values, volume shifts, and unusual data patterns before they affect AI outputs.
- Root-cause visibility: Trace quality issues back to the source system, pipeline step, or business rule that created them.
- Establish Context-Aware Data Governance AI needs governance that understands both structured and unstructured data.
- Context mapping: Classify documents, tickets, logs, emails, and records by sensitivity, ownership, purpose, and permitted use.
- Access control: Protect sensitive data before it enters AI workflows, especially in regulated or customer-facing environments.
- Shift from More Data to Right Data Adding more data can weaken AI when the data is irrelevant, outdated, or poorly represented.
- Curation over volume: Prioritize data that is accurate, current, representative, and tied to the business decision.
- Gap handling: Use enrichment or synthetic data carefully when real-world data is sparse, biased, or incomplete.
- Close the Loop with Human-in-the-Loop Feedback AI performance changes as data, users, and business rules change.
- Continuous evaluation: Capture user corrections, rejected recommendations, edge cases, and recurring output errors.
- Feedback loops: Send these signals back into data pipelines, model testing, retrieval logic, and governance reviews.
- Cultivate a Cross-Functional Culture Data quality improves when business and technology teams share accountability.
- Data literacy: Help business teams understand definitions, quality rules, exceptions, and how data shapes AI decisions.
- Shared KPIs: Align data, AI, engineering, risk, compliance, and business teams around quality thresholds and outcomes.
Data quality for AI does not require perfect data. It requires data that is trusted, owned, monitored, and fit for the decisions AI will support.
TxMinds’ Role in Building Data Foundations AI Can Trust
At TxMinds, we help enterprises strengthen trusted data foundations for AI by connecting governance, quality engineering, modernization, and AI-native delivery. We work with leaders who need reliable enterprise data, not isolated cleanup projects.
We assess critical data domains, identify quality gaps, define ownership models, and build controls that support AI-ready delivery. Our work covers data profiling, cleansing, enrichment, lineage, metadata, governance frameworks, and continuous monitoring.
We also help teams modernize data pipelines so information remains accurate, secure, consistent, and usable across analytics and AI workflows. The goal is practical. We help enterprises reduce avoidable AI risk, improve trust in outputs, and scale AI with stronger confidence.
For organizations preparing to scale AI, data quality for AI becomes the foundation for dependable decisions, governed automation, and long-term business value. To explore stronger data foundations for AI adoption, connect with our team.
VP and Global Head Data & AI Practice
Results-oriented Data Analytics & AI Specialist with 24+ years of experience in multiple roles, including Practice Leader with P&L ownership. Expert in building Data Analytics practices, defining market strategies, and leading large-scale transformation initiatives. Skilled in Business Intelligence, Data Engineering, Cloud platforms (Azure, AWS, GCP), AI/ML, and Data Governance, with a strong focus on customer-centric solutions and strategic alliances.
FAQs
Why is data quality for AI important?
Data quality for AI is important because AI systems depend on the accuracy, completeness, and context of the data they use. Poor data can lead to unreliable recommendations, weak automation, and decisions that business teams cannot trust.
Why do AI projects fail because of data quality?
AI projects often fail because data quality issues appear too late in delivery. Fragmented systems, duplicate records, stale data, unclear ownership, and weak lineage can prevent AI from producing reliable outputs in real business workflows.
What does AI readiness data mean?
AI readiness data means data that is fit for a specific AI use case. It should be accurate, governed, secure, traceable, current, and monitored for the workflow or decision the AI system will support.
How can leaders improve data quality for AI?
Leaders can improve data quality for AI by assigning ownership, monitoring data pipelines, standardizing business definitions, strengthening governance, and creating feedback loops from AI outputs back into data and model improvement.
Discover more