The digital universe is expanding faster than ever, with an estimated 400 million terabytes of data generated daily in 2025. This tidal wave of information is both an opportunity and a challenge. For enterprises ready to act, it represents the fuel for innovation, smarter decisions, and market leadership.
To harness this potential, businesses need cloud data pipelines; systems engineered to capture, process, and deliver data continuously and reliably. When built correctly, these pipelines enable faster insights, personalized experiences, and predictive analytics that drive competitive advantage.
Many believe cloud data pipelines are too complex, expensive, or hard to scale. With smart architecture, the right tools, and proven best practices, these challenges can become opportunities. A well-built pipeline does more than transport data. It unlocks insights that drive decisive action and deliver measurable impact.
This blog explains the best practices, strategies, and tools to build cloud data pipelines that are scalable, reliable, and cost-efficient.
Key Takeaways
Data sources, data ingestion, data processing, and data delivery are some important components of modern data pipelines.
Cloud pipelines enable faster and real-time decision-making across business functions.
Scalable and efficient pipelines drive cost savings, innovation, and growth opportunities.
Designing smart pipelines can cut operational costs by 15% to 30%.
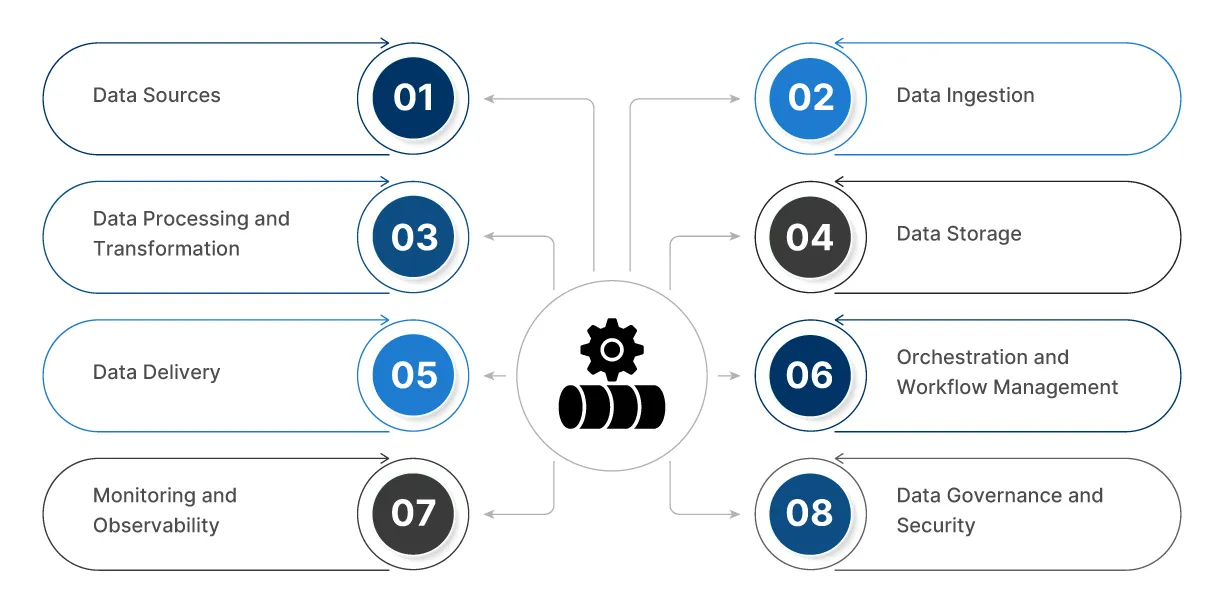
Components of Modern Data Pipelines
Understanding the fundamental building blocks of cloud data pipelines is crucial for designing and deploying systems that effectively convert raw data into actionable insights. Each component plays a specific role in ensuring data flows reliably, securely, and efficiently from source to end user.
1. Data Sources
Every pipeline starts with the data itself. Sources include operational databases, SaaS platforms, REST APIs, application and system logs, streaming IoT devices, or third‑party datasets. These may reside on‑premises, in the cloud, or hybrid environments. Because each source can have different formats and protocols, from structured tables to unstructured JSON or XML, the pipeline must use flexible connectors to integrate them efficiently.
2. Data Ingestion
Raw data enters the pipeline either in batch mode, processing large volumes at scheduled intervals, or streaming mode for real‑time event capture and analytics. Scalability and fault tolerance are essential here. By 2025, the world will generate around 463 exabytes of data daily, driving the demand for ingestion systems that can continuously process data without bottlenecks.
3. Data Processing and Transformation
Data is cleaned, validated, enriched, and structured in this stage for accuracy and usability. Pipelines may follow ETL (transform before storage) or ELT (transform after storing) approaches. Poor data quality impacts analytics for up to 95% of businesses, making robust transformation processes essential to ensure reliable insights.
4. Data Storage
Processed data must be stored in a form that supports easy access and analysis. Data lakes (e.g., AWS S3, Azure Data Lake Storage) can cost-effectively store large volumes of raw and semi‑structured data. In contrast, data warehouses (e.g., Google BigQuery, Snowflake, Amazon Redshift) are optimized for structured, analytical queries. Performance can be improved by using partitioning, compression, and columnar formats like Parquet and Avro.
5. Data Delivery
Once prepared, data must be delivered to the right people, tools, and systems. This can be through BI dashboards, APIs, data marts tailored to specific business units, or machine learning pipelines. Effective delivery ensures decision‑makers receive consistent, accurate, and timely data they can act on.
6. Orchestration and Workflow Management
Because pipelines involve many interdependent steps, orchestration ensures that jobs run in the correct order, with dependencies tracked and errors handled automatically. Tools like Apache Airflow, Azure Data Factory, and Prefect make scheduling workflows easier, triggering events, and recovering quickly from failures.
7. Monitoring and Observability
Continuous monitoring tracks data freshness, latency, throughput, and errors. Real-time alerts help identify and address issues proactively. Downtime in critical data pipelines can cost organizations upwards of $300,000 per hour, underscoring the value of robust monitoring.
8. Data Governance and Security
Strong governance ensures data compliance and trust. Governance ensures compliance and data trustworthiness through lineage tracking, role‑based security, and encryption in transit and at rest. Since the average data breach cost reached $4.45 million in 2025, security needs to be embedded from the ground up to protect sensitive information and maintain regulatory compliance.
These eight components form a fully operational cloud data pipeline, from capturing raw data to delivering secure, actionable insights. The better each part is designed, the faster and reliably your organization can turn data into results.
Best Practices for Cloud Data Pipeline Design
A cloud data pipeline isn’t just a set of connected tools, it’s the backbone of your analytics. Done right, it delivers accurate, timely insights at scale so decision-makers can act with confidence. When done wrong, it creates bottlenecks, bad insights, and wasted spending.
1. Start With Clear Business Goals
Before touching any tech, define what success looks like. Is it having dashboards refresh every 10 minutes? Guaranteeing 99.9% uptime? Keeping costs under a set limit? These metrics align teams and prevent wasted effort on “nice-to-have” features that don’t serve the core business need.
2. Build for Scale and Reliability
Your pipeline should grow with your data, not choke on it. Use cloud-native features like auto-scaling, serverless functions, and elastic clusters to handle varying workloads. Add safety measures like retries, circuit breakers, and redundancy, so it keeps running smoothly even when something breaks. Scalability remains the top reason for cloud migration, cited by 71% of decision-makers in 2025
3. Keep It Modular
Break your pipeline into logical stages: ingestion, processing, storage, and delivery. This makes fixing problems, upgrading tech, or adding capacity easier without disrupting the entire system. Each stage can be monitored and optimized independently to ensure maximum efficiency. Clear separation also helps teams innovate faster, experiment safely, and scale confidently as data volumes grow.
4. Automate and Monitor Proactively
Orchestration tools such as Apache Airflow, Azure Data Factory, or AWS Step Functions can schedule tasks, manage dependencies, and recover from failures without constant human oversight. Pair that with real-time monitoring and alerts so issues are spotted and fixed before they impact end users, cutting manual intervention by as much as 70%.
5. Make Data Quality Non-Negotiable
Data errors creep in at every stage. If you don’t catch them early, your analytics suffer. Build automated validation, cleansing, and anomaly detection into the pipeline to maintain accuracy and consistency from ingestion to delivery. Continuous monitoring ensures issues are flagged in real time. This proactive approach safeguards decision-making and preserves trust in your data across the organization.
6. Build Security Into the Foundation
Don’t bolt on security later, but design with it in mind from day one. Use role-based access controls, encrypt data in transit and at rest, and maintain full lineage tracking for compliance with GDPR, HIPAA, or CCPA. In 2025, the global average data breach cost is $4.44 million; a slight drop from 2024, but the U.S. average has surged to $10.22 million (IBM, HIPAA Journal). For breaches involving shadow AI, costs climb even higher, averaging INR 220 million (≈ USD 2.7M) in India.
7. Store Smarter, Spend Less
Choose efficient formats like Parquet or Avro. And partition data to speed queries. Apply lifecycle rules to archive or delete data you no longer need; cutting cloud storage costs by up to 30% without sacrificing performance. Compress and index data wherever possible to further improve retrieval times. Regularly review storage patterns to eliminate waste and ensure the pipeline remains lean and cost-effective.
8. Plan for Change
Data environments evolve with new sources, formats, and analytics demands. Using microservices and containerized components keeps your pipeline adaptable, letting you plug in new capabilities (like AI/ML workflows) without painful overhauls. With AI adoption accelerating, pipelines that can integrate machine learning and generative AI models quickly will turn technological shifts into competitive advantages.
The Strategic Impact of Cloud Data Pipelines
Cloud data pipelines today do more than just transmit data; they also help businesses develop, become more efficient, and generate new ideas. They take raw data and turn it into useful information that helps teams make decisions faster and better.
Faster Decision-Making: With real-time ingestion and processing, insights reach decision-makers instantly. Companies can quickly respond to changes in the market, client behavior, and problems with their operations.
Improved Customer Experiences: Reliable pipelines make it possible to give personalized deals, make suggestions that change over time, and offer services that predict what will happen next. Companies who use real-time data say their customers are 20% more likely to interact with them.
Cost Optimization: Pipelines reduce on human work and extra cloud costs by automating data workflows and making the best use of storage. Smart pipes can cut operational costs by 15% to 30%.
Enables Innovation: Scalable pipelines let teams try out new models, AI apps, and ways to use analytics. In a market driven by data, businesses can come up with new ideas faster and stay ahead of the competition.
Enhances Revenue Opportunities: Predictive analytics and AI-driven initiatives rely on clean, accurate, and timely data. Companies can run focused advertising, find new market opportunities, and set prices that make the most money.
How TxMinds Drives Transformation in Data Pipelines
TxMinds helps organizations build modern, scalable cloud data pipelines that turn raw data into actionable insights with our cloud data engineering services. We design customized architectures for real-time analytics or hybrid cloud setups, modernize legacy systems with minimal downtime, and implement automation to streamline workflows and improve reliability. With embedded data quality checks, governance controls, and continuous performance tuning, TxMinds ensures accuracy, compliance, and cost efficiency.
By working closely with client teams and providing ongoing support, they empower businesses to manage and evolve their pipelines effectively, delivering faster, secure, and smarter data-driven outcomes.
Summary
Cloud data pipelines are the backbone of modern data-driven businesses, enabling the seamless movement of information from capture to insight. When designed with scalability, security, and governance in mind, they empower faster decisions, improve operational efficiency, and unlock new opportunities for innovation. Partnering with experts in cloud data engineering services like TxMinds helps organizations accelerate pipeline implementation, optimize performance, and ensure long-term adaptability, turning raw data into a true strategic asset.
Amar Jamadhiar is the Vice President of Delivery for TxMind's North America region, driving innovation and strategic partnerships. With over 30 years of experience, he has played a key role in forging alliances with UiPath, Tricentis, AccelQ, and others. His expertise helps Tx explore AI, ML, and data engineering advancements.
FAQs
What is a cloud data pipeline, and why is it important?
A cloud data pipeline is a system that always and reliably collects, processes, and sends data. It speeds up insights, helps with analytics and AI operations, and makes sure that decision-makers get reliable, timely information that helps the business.
How can I ensure my data pipeline scales as my business grows?
Modular design, cloud-native features like auto-scaling and serverless services, and proactive monitoring all help with scalability. You can expand capacity or modify parts without stopping the system by dividing pipelines into stages like ingestion, processing, storage, and delivery.
What are the best practices to maintain data quality and accuracy?
At every level, automate validation, cleaning, and finding anomalies. Add continuous monitoring and real-time alerts to this to stop errors from spreading, which will make sure that the data used for analytics and decision-making is reliable.